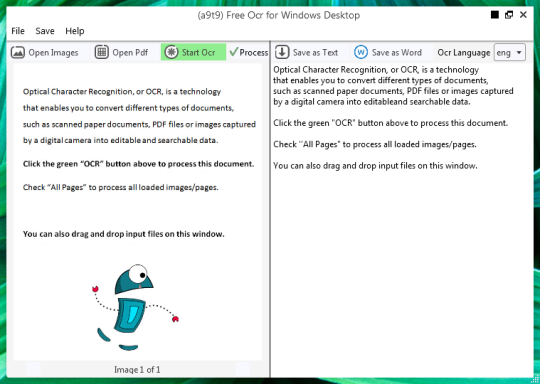
OCR ซอฟต์แวร์ฟรีที่จะดึงข้อความจากไฟล์ภาพและรายการในรูปแบบ PDF อินเตอร์เฟซผู้ใช้แบบกราฟิก (GUI) สำหรับเครื่องยนต์ Tesseract OCR.
แอปพลิเคง่ายในการติดตั้งและที่สำคัญกว่านั้นอิสระในการใช้โอเพนซอร์สและแอดแวร์ 100% และสปายแวร์ฟรี
คุณสามารถเปิดภาพหรือไฟล์ PDF เนื้อหาของแฟ้มแหล่งที่มาจะถูกแสดงในหน้าต่างด้านซ้าย ถ้าเอกสารของคุณเป็นมากกว่าหนึ่งหน้าหรือถ้าคุณเปิดเอกสารหลายหน้าให้ใช้ลูกศรที่ด้านล่างเพื่อสลับระหว่างพวกเขา,
คุณเริ่มต้น OCR โดยคลิกที่ปุ่มสีเขียว OCR, และคุณจะเห็นผลในหน้าต่างด้านขวาที่สอง ข้อความเอาท์พุทที่สามารถบันทึกเป็นไฟล์ข้อความหรือเอกสาร Word.
แต่น่าเสียดายที่มีคุณภาพการแปลงไม่ดีดังนั้น เบื้องหลังจะใช้ Tesseract โอเพนซอร์สเครื่องยนต์ OCR ที่มีคุณภาพแตกต่างกันไปจากภาษาภาษา -. เพื่อไปข้างหน้าและการทดสอบถ้ามันจะเพียงพอสำหรับความต้องการของคุณ
สำหรับนักพัฒนาซอฟต์แวร์และ geeks: OCR ฟรีสำหรับเครื่องมือ Windows Desktop เป็นหลักอินเตอร์เฟซผู้ใช้แบบกราฟิก front-end (GUI) สำหรับเครื่องยนต์ Tesseract OCR ซอร์สโค้ดเต็มสามารถใช้ได้ (ใบอนุญาต GPL).
เครื่องยนต์ OCR ของซอฟต์แวร์ที่รองรับภาษา OCR ต่อไปนี้: อังกฤษ, ฝรั่งเศส, อิตาลี, เยอรมัน, สเปน, บราซิลโปรตุเกสและดัตช์ เริ่มต้นด้วย 3 รุ่นที่จะสามารถรับรู้ภาษาอาหรับ, บัลแกเรีย, คาตาลัน, ภาษาจีน (ประยุกต์และดั้งเดิม), โครเอเชีย, เช็ก, เดนมาร์ก, ดัตช์, อังกฤษ, เยอรมัน (มาตรฐานและสคริปต์ Fraktur), กรีก, ฟินแลนด์, ฝรั่งเศส, ฮิบรูภาษาฮินดี, ฮังการี, อินโดนีเซีย, อิตาลี, ญี่ปุ่น, เกาหลี, ลัตเวียลิทัวเนีย, นอร์เวย์, โปแลนด์, โปรตุเกส, โรมาเนีย, รัสเซีย, เซอร์เบีย, สโลวัก (มาตรฐานและสคริปต์ Fraktur), สโลวีเนีย, สเปน, สวีเดน, ตากาล็อก, ทมิฬ, ไทย, ตุรกี, ยูเครนและเวียดนาม
ความคิดเห็นที่ไม่พบ