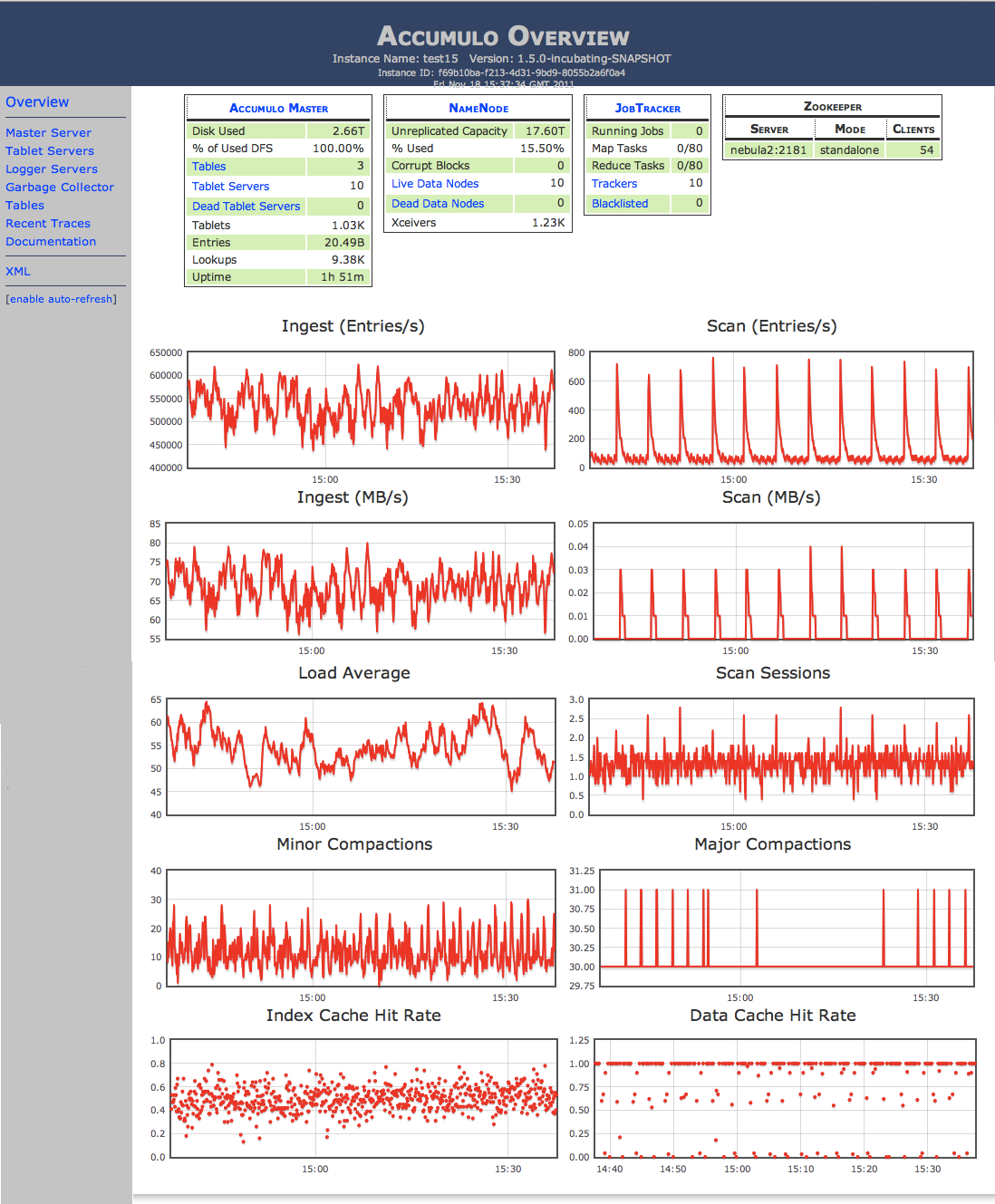
ภาพหน้าจอของซอฟแวร์:
รายละเอียดซอฟแวร์:
รุ่น: 1.7.0 การปรับปรุง
วันที่อัพโหลด: 4 Jun 15
ผู้พัฒนา: Apache Software Foundation
การอนุญาต: ฟรี
ความนิยม: 151
Apache Accumulo ตอบโต้กับผู้ใช้ได้ของเทคโนโลยีต่างๆจาก BigTable ของ Google เพื่อ Apache Hadoop เจริญเติบโตอย่างรวดเร็ว และ Zookeeper
เมื่อเทียบกับระบบ BigTable ของ Google Accumulo มีการปรับปรุงบางส่วนของของตัวเอง
เหล่านี้รวมถึงข้อ จำกัด การเข้าถึงของเซลล์ตามตารางระบบด้านเซิร์ฟเวอร์สำหรับการจัดการคู่ค่าคีย์ในช่วงเวลาที่ต้องการและในสภาวะที่เหมาะสมและจำนวนมากของ API ลูกค้า
ฐานข้อมูลไม่แน่นอนสำหรับการเรียกใช้เว็บไซต์ของคุณทุกวันและมีการกำหนดเป้าหมายสำหรับสภาพแวดล้อมคลาวด์คอมพิวเตอร์ที่นักพัฒนาต้องจัดการจำนวน humongous ข้อมูล
มีอะไรใหม่ ในข่าวประชาสัมพันธ์ฉบับนี้.
- การใช้ Hadoop CredentialProviders
- เข้าสู่ระบบเขียนล่วงหน้าประสิทธิภาพการซิงค์
- ไมเนอร์-บีบอัดไม่ก้าวร้าวพอ
- บันทึกเขียนล่วงหน้าการดำเนินการซิงค์
- การเพิ่มประสิทธิภาพ HeapIterator
มีอะไรใหม่ ในรุ่น 1.6.2:
- การใช้ Hadoop CredentialProviders
- เข้าสู่ระบบเขียนล่วงหน้าประสิทธิภาพการซิงค์
- ไมเนอร์-บีบอัดไม่ก้าวร้าวพอ
- บันทึกเขียนล่วงหน้าการดำเนินการซิงค์
- การเพิ่มประสิทธิภาพ HeapIterator
มีอะไรใหม่ ในรุ่น 1.6.0:
- ที่อยู่ IP บริการ
- ปริมาณการสนับสนุนหลาย
- namespaces ตาราง
- กลยุทธ์การบดอัดแบบเสียบ
- การกลายพันธุ์เงื่อนไข
- กลุ่มถิ่นที่อยู่ในความทรงจำ
- ข้อ จำกัด ขนาดขึ้นอยู่กับตารางใหม่
มีอะไรใหม่ ในรุ่น 1.4.1:.
- เลือกตรวจสอบ swappiness บนเซิร์ฟเวอร์ทุก
- การสนับสนุนการทำงานบนด้านบนของ HDFS ที่เปิดใช้งาน Kerberos.
- ให้วิธีการในการรวบรวมสถิติระบบ API.
มีอะไรใหม่ ในรุ่น 1.4.0:
- การรวมแท็บเล็ต
- ลบที่มีประสิทธิภาพของช่วงแถว
- บดอัดของช่วงแถว
- โคลนตาราง
- ชะตากรรม: ทนความผิดผู้ปฏิบัติการ มาใช้เพื่อให้การดำเนินการอยู่รอดตารางต้นแบบเริ่มต้นใหม่.
- การดำเนินงานของตารางพร้อมกันดำเนินการอย่างถูกต้อง
- โหลดจำนวนมากจะทำในขณะนี้โดยหลักและแท็บเล็ตเซิร์ฟเวอร์และใช้ชะตากรรมที่จะอยู่รอดรีสตาร์ทเซิร์ฟเวอร์.
- หลายระดับดัชนี RFile
- ผสานบีบอัดเล็กน้อย
- เวลาตรรกะสำหรับการนำเข้าจำนวนมาก </ li>
ความคิดเห็นที่ไม่พบ