ยอมรับข้อความจากภาพโดยใช้ Tesseract OCR เครื่องยนต์ที่ใช้เทคโนโลยีคลาวด์
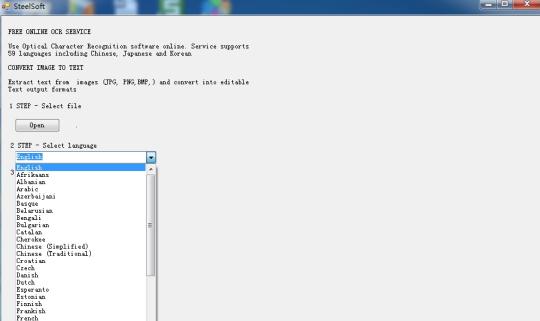
การใช้ซอฟต์แวร์ Optical Character ยอมรับออนไลน์ บริการรองรับ 59 ภาษารวมทั้งจีน, ญี่ปุ่นและเกาหลี สารสกัดจากข้อความจากภาพ (JPG, PNG, BMP, TIF) และแปลงเป็นรูปแบบการแสดงผลข้อความที่สามารถแก้ไขได้
มันขึ้นอยู่กับเทคโนโลยีคลาวด์และเครื่องยนต์ OCR ที่มีชื่อเสียงมาก (Tesseract เครื่องยนต์ OCR) ดังนั้นมีเพียงหลายร้อยกิโลไบต์ในขนาด แต่ก็สามารถดึงข้อความใน 59 ภาษาจากภาพ
มันสนับสนุนภาษาเพิ่มเติมได้ที่: บัลแกเรีย, คาตาลัน, เช็ก, เดนมาร์ก, ดัตช์, อังกฤษ, ฟินแลนด์, ฝรั่งเศส, เยอรมัน, กรีก, ฮังการี, อินโดนีเซีย, อิตาลี, ลัตเวียลิทัวเนีย, นอร์เวย์, โปแลนด์, โปรตุเกส, โรมาเนีย, รัสเซีย, เซอร์เบีย, สโลวาเกีย, สโลวีเนีย , สเปน, สวีเดน, ภาษาตากาล็อก, ตุรกี, ยูเครน, เวียดนาม ฯลฯ
มีอะไรใหม่ ในข่าวประชาสัมพันธ์ฉบับนี้..
เวอร์ชั่น 5.0 รวมถึง UE ปรับปรุง

ความคิดเห็นที่ไม่พบ