
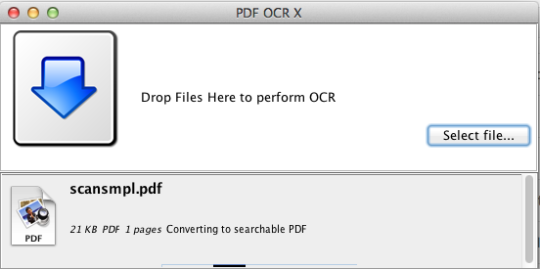
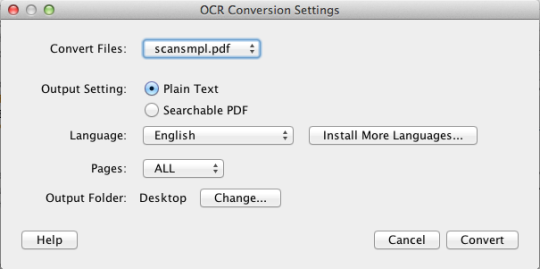
PDF OCR X เป็นยูทิลิตี้แบบลากและวางที่เรียบง่ายสำหรับ Mac OS X ที่แปลงไฟล์ PDF และรูปภาพของคุณเป็นเอกสารข้อความหรือค้นหาได้ ใช้เทคโนโลยี OCR (optical character recognition) ขั้นสูงเพื่อดึงข้อความของ PDF (หรือภาพ) แม้ว่าจะมีข้อความอยู่ในภาพ นี่เป็นประโยชน์อย่างยิ่งสำหรับการจัดการกับไฟล์ PDF และภาพที่สร้างผ่านฟังก์ชัน Scan-to-PDF ในเครื่องสแกนเนอร์หรือเครื่องถ่ายเอกสาร สนับสนุนมากกว่า 60 ภาษาสำหรับ OCR เครื่องมือ OCR จะขึ้นอยู่กับ Tesseract Community Edition สนับสนุนไฟล์ PDF แบบหน้าเดียว (หรือหน้าแรกของไฟล์ PDF หลายหน้า) สำหรับการสนับสนุน PDF หลายหน้าคุณควรอัปเกรดเป็น Enterprise Edition
มีอะไรใหม่ ในรุ่นนี้:
เวอร์ชัน 2.1.1 เพิ่มการสนับสนุน Mojave และปรับปรุง UI ในจอแสดงผล Retina
มีอะไรใหม่ ในเวอร์ชัน 2.0.8:
แก้ไขปัญหาเกี่ยวกับการจัดการไฟล์ PDF บางประเภทที่มีการหมุนเวียน
ข้อ จำกัด :Community Edition จำกัด เฉพาะไฟล์ PDF และภาพเดียวในรูปแบบต่างๆ



ความคิดเห็นที่ไม่พบ